¿Qué son las CNN?
Comprendiendo las CNN
Las Redes Neuronales Convolucionales, o CNN, son una clase de algoritmos de aprendizaje profundo que se utilizan principalmente para procesar y reconocer datos visuales. Su diseño está inspirado en la forma en que el cerebro humano procesa la información visual. Las CNN pueden detectar patrones y dependencias espaciales en las imágenes a través de su estructura jerárquica, lo que las hace muy efectivas en tareas como la clasificación de imágenes, la detección de objetos y el reconocimiento facial.
La fortaleza de las CNN radica en su capacidad para aprender automáticamente características de imágenes de entrada sin procesar, eliminando la necesidad de extracción manual de características. Esto se logra a través de múltiples capas: capas de convolución que aplican filtros para capturar características, capas de agrupamiento que reducen la carga computacional y capas completamente conectadas que realizan la clasificación final después de aprender las características.
Componentes Clave
Las CNN se construyen sobre una serie de componentes que trabajan juntos para procesar imágenes de una manera que imita la percepción visual humana. Las capas de convolución aplican filtros para detectar varias características como bordes y texturas. Las capas de agrupamiento luego reducen las dimensiones espaciales, haciendo que el proceso sea más eficiente computacionalmente sin perder información crucial. Las funciones de activación añaden no linealidad, permitiendo que las CNN aprendan patrones más complejos. Finalmente, las capas completamente conectadas son responsables de clasificar las características aprendidas en categorías específicas.
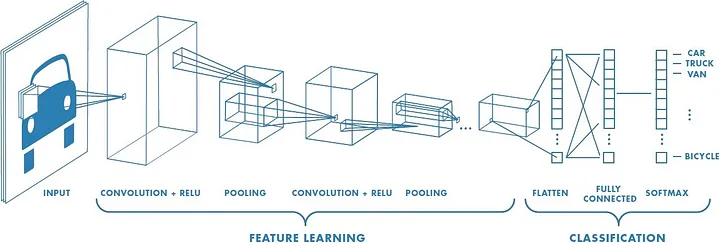
Las CNN se han convertido en una herramienta fundamental en el campo de la visión por computadora, permitiendo a las máquinas analizar y comprender datos visuales. Su capacidad para aprender y extraer características automáticamente, sin necesidad de una extensa intervención humana, las ha hecho indispensables en muchas aplicaciones del mundo real.
Cómo Funcionan las CNN
Las Redes Neuronales Convolucionales operan aprendiendo representaciones jerárquicas de los datos, lo que les permite capturar tanto características de bajo nivel como de alto nivel de manera estructurada. Las primeras capas de la red se centran en detectar patrones simples como bordes o texturas, mientras que las capas más profundas extraen características más complejas como formas u objetos. Este enfoque jerárquico permite que las CNN aborden de manera efectiva tareas sofisticadas como la clasificación de imágenes y la detección de objetos.
El proceso comienza con una imagen de entrada que se analiza a través de múltiples capas de convolución y agrupamiento. Estas capas colaboran para detectar y refinar características esenciales a diferentes niveles de abstracción. Las capas convolucionales enfatizan la extracción de características aplicando filtros especializados, mientras que las capas de agrupamiento reducen las dimensiones espaciales, asegurando la eficiencia computacional sin descartar información crítica. Juntas, estos componentes preparan los datos para la etapa final de clasificación o predicción, donde las capas completamente conectadas aprovechan las características aprendidas para generar salidas precisas.
Al combinar estos mecanismos, las CNN logran una precisión notable en la interpretación y categorización de datos visuales. Esta capacidad ha revolucionado campos como la visión por computadora, convirtiendo a las CNN en herramientas indispensables para analizar imágenes complejas.
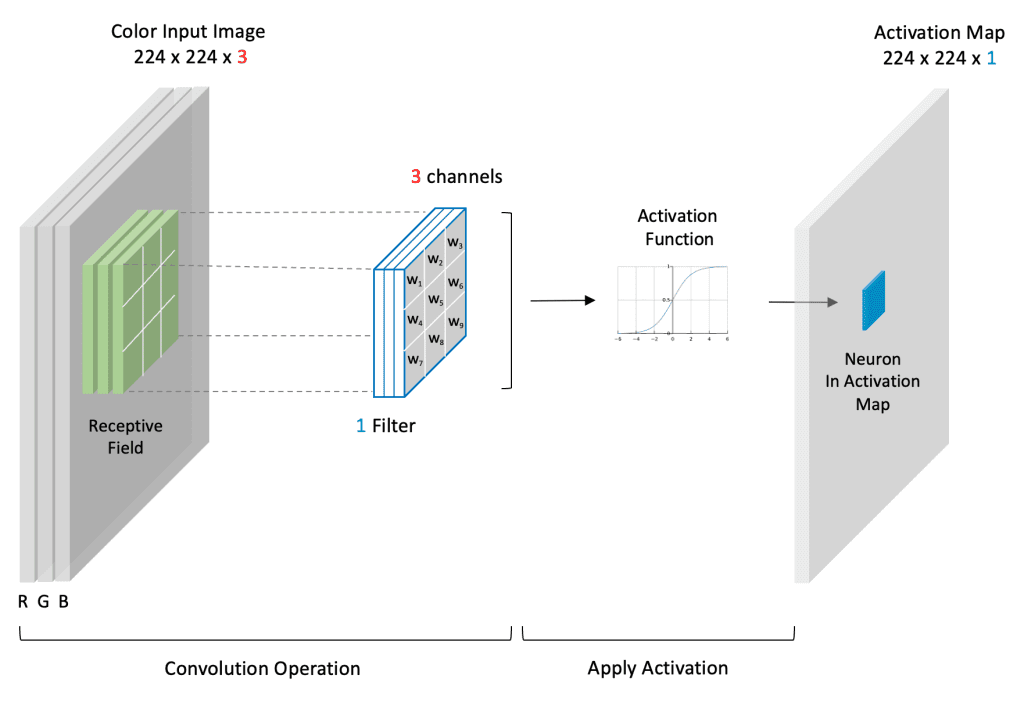
Entrenamiento de CNN
Visión General del Proceso de Entrenamiento
Las Redes Neuronales Convolucionales (CNN) se entrenan utilizando técnicas de aprendizaje supervisado, que requieren datos etiquetados para aprender. El objetivo principal es minimizar la diferencia entre los valores predichos y los reales utilizando una función de pérdida. El proceso implica múltiples pasos para asegurar que la red aprenda representaciones precisas de los datos.
Los elementos clave en el entrenamiento de una CNN incluyen preparar los datos, seleccionar una función de pérdida apropiada, utilizar optimizadores para ajustar los pesos y aplicar retropropagación para afinar la red. Estos elementos trabajan juntos para refinar el modelo a lo largo de múltiples iteraciones, mejorando su precisión con cada pasada.
Pasos Clave en el Entrenamiento de una CNN
El proceso de entrenamiento se divide en cuatro pasos principales:
- Preparación de Datos: Las imágenes se preprocesan y normalizan para asegurar uniformidad en el conjunto de datos.
- Función de Pérdida: La función de pérdida mide el error entre las etiquetas predichas y reales. Las funciones de pérdida comunes incluyen la entropía cruzada para tareas de clasificación.
- Optimizador: El optimizador ajusta los pesos de la red para minimizar la función de pérdida. Los optimizadores populares incluyen el Descenso de Gradiente Estocástico (SGD) y Adam.
- Retropropagación: Esta técnica calcula los gradientes de la función de pérdida y actualiza los pesos del modelo para reducir los errores.
Algoritmos de Optimización Comunes
Durante el entrenamiento, algoritmos de optimización como el Descenso de Gradiente Estocástico (SGD) y Adam desempeñan un papel crucial en la minimización de la función de pérdida. La tasa de aprendizaje es un parámetro importante que determina el tamaño de los pasos dados durante la optimización. Una tasa de aprendizaje bien ajustada puede acelerar significativamente el entrenamiento y mejorar el rendimiento del modelo.

El entrenamiento de una CNN es una parte crítica del proceso de aprendizaje automático, ya que permite que la red aprenda los patrones necesarios a partir de datos etiquetados. Una preparación adecuada de los datos, la selección de la función de pérdida y las técnicas de optimización son esenciales para construir un modelo robusto y eficiente.
Evaluación del Rendimiento de la CNN
Después de entrenar una Red Neuronal Convolucional (CNN), evaluar su rendimiento es crucial para asegurar su efectividad. La evaluación del rendimiento se lleva a cabo típicamente en un conjunto de datos de prueba separado para verificar qué tan bien el modelo se generaliza a datos no vistos. Este paso ayuda a identificar el sobreajuste potencial y proporciona información sobre las fortalezas y debilidades del modelo.
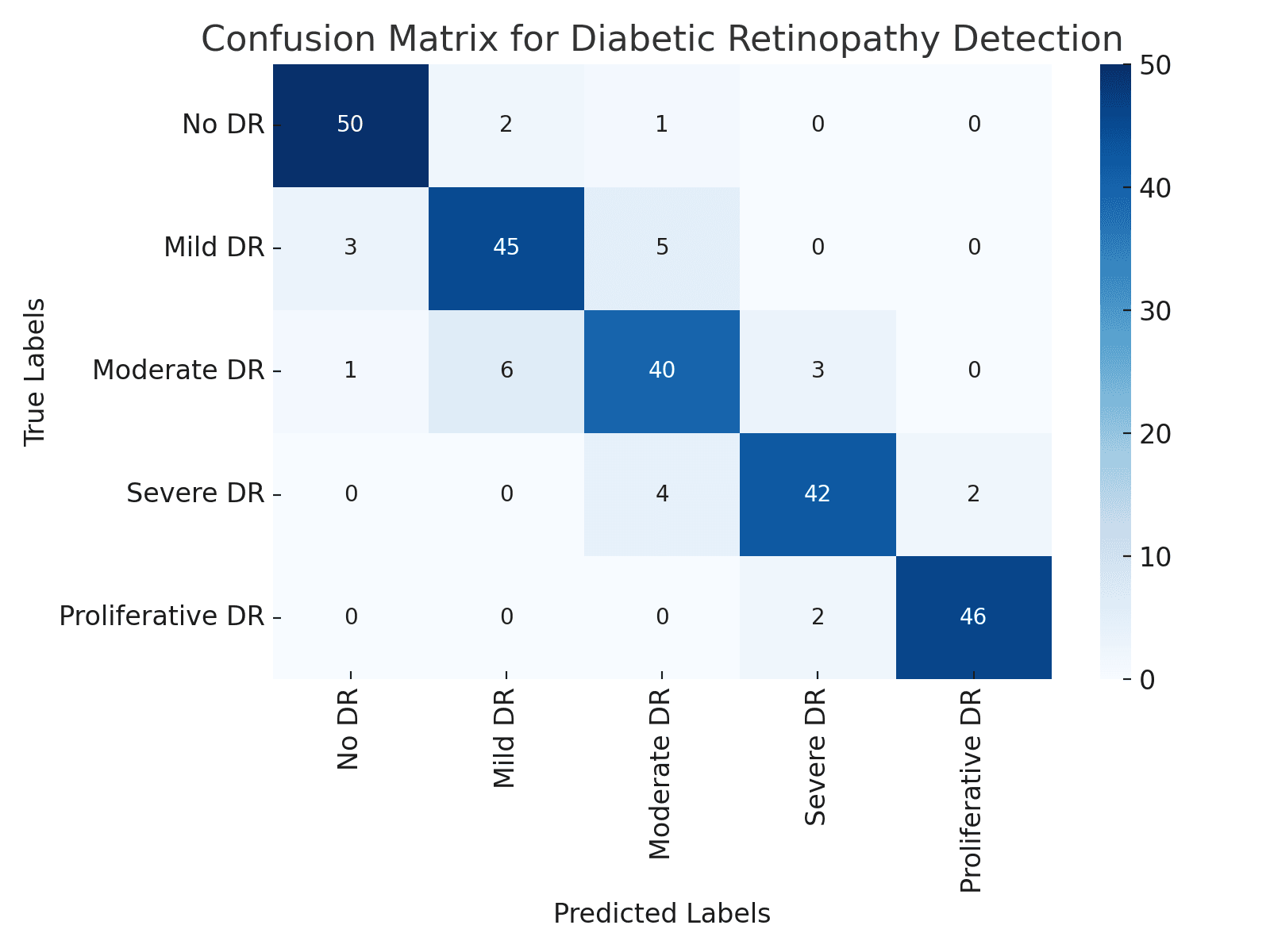
Una matriz de confusión es una herramienta de visualización poderosa para evaluar el rendimiento de la CNN. Descompone las predicciones correctas e incorrectas a través de las clases, ofreciendo una perspectiva detallada sobre el comportamiento del modelo. Por ejemplo, al detectar Retinopatía Diabética a partir de imágenes médicas, la matriz puede resaltar áreas específicas donde el modelo sobresale o tiene dificultades, guiando refinamientos adicionales.
Comprender los matices del rendimiento de la CNN a través de visualizaciones es fundamental para refinar modelos y asegurar su fiabilidad en aplicaciones del mundo real. Herramientas como las matrices de confusión transforman métricas en bruto en información útil, impulsando la mejora continua y fomentando la confianza en los sistemas de IA.
Arquitecturas de CNN
LeNet-5 (1998)
LeNet-5 es una red convolucional pionera diseñada para clasificar dígitos escritos a mano. Se aplicó para el reconocimiento automático de dígitos en cheques utilizando imágenes en escala de grises de 32x32 píxeles.
Aunque LeNet-5 demostró un rendimiento sólido, su capacidad para procesar imágenes de mayor resolución está limitada por los recursos computacionales.
AlexNet (2012)
AlexNet, introducido en 2012, fue un avance en el aprendizaje profundo para la clasificación de imágenes, utilizando cinco capas para aprender patrones de grandes conjuntos de datos. Tuvo un impacto significativo en el campo de la visión por computadora.
En dominios como el análisis de documentos legales, AlexNet podría utilizarse para clasificar imágenes de contratos o documentos judiciales, mejorando la eficiencia del flujo de trabajo.
ResNet (2015)
ResNet aborda el problema del desvanecimiento del gradiente con conexiones residuales que permiten redes más profundas. Esto le permite aprender de manera más efectiva incluso con muchas capas.
En turismo, ResNet podría clasificar imágenes de destinos, ayudando a las empresas de viajes a dirigir sus esfuerzos de marketing y recomendar lugares a los viajeros.
GoogLeNet (2014)
GoogLeNet, introducido en 2014, utiliza módulos Inception para mejorar la eficiencia, permitiendo que la red procese información en múltiples niveles mientras reduce la carga computacional.
En el comercio minorista, GoogLeNet podría analizar imágenes de productos para la categorización y la gestión de inventarios, optimizando las operaciones y mejorando la precisión de la búsqueda de productos.
MobileNet (2017)
MobileNet está optimizado para dispositivos móviles, utilizando convoluciones separables en profundidad para reducir parámetros mientras mantiene la precisión.
En recursos humanos, MobileNet podría utilizarse para clasificar currículos o analizar perfiles de solicitantes de empleo, facilitando la evaluación de las calificaciones por parte de los equipos de RRHH.
VGG-16 (2014)
VGG-16 es una CNN profunda con 16 capas, diseñada para lograr alta precisión en tareas de clasificación de imágenes y detección de objetos. Ha sido ampliamente adoptada en investigaciones y aplicaciones prácticas.
Aplicaciones de las Redes Neuronales Convolucionales
Casos de Uso Versátiles de las CNN
Las Redes Neuronales Convolucionales (CNN) han revolucionado la visión por computadora al permitir que las máquinas interpreten y procesen datos visuales con una precisión inigualable. Su estructura jerárquica permite la extracción automática de características, lo que las hace indispensables en numerosos campos:
Clasificación de Imágenes
Asignar imágenes a categorías predefinidas, como identificar especies de animales o tipos de vehículos.
Detección de Objetos
Localizar y categorizar múltiples objetos dentro de una imagen, esencial para la conducción autónoma y sistemas de vigilancia.
Segmentación de Imágenes
Dividir una imagen en segmentos para identificar límites y objetos, crucial en imágenes médicas para la detección de tumores.
Reconocimiento Facial
Identificar o verificar individuos analizando características faciales, ampliamente utilizado en sistemas de seguridad y autenticación.
Análisis de Imágenes Médicas
Asistir en el diagnóstico de enfermedades analizando imágenes médicas, como detectar retinopatía diabética.
Conducción Autónoma
Permitir que los vehículos comprendan su entorno reconociendo señales de tráfico, peatones y obstáculos.
Análisis de Video
Interpretar datos de video para reconocimiento de acciones, detección de eventos y resumido.
Estudio de Caso: Detección de Retinopatía Diabética
La Retinopatía Diabética (RD) es una de las principales causas de ceguera, resultante de la diabetes prolongada que afecta la retina. La detección temprana es vital para un tratamiento efectivo y la preservación de la visión. Las CNN se han vuelto fundamentales en la automatización de la detección y clasificación de la RD a partir de imágenes retinianas.
Al entrenar en grandes conjuntos de datos de imágenes de fondo retiniano, las CNN pueden identificar características indicativas de la RD, como microaneurismas, hemorragias y exudados. Los estudios han demostrado que los modelos basados en CNN logran alta sensibilidad y especificidad en la detección de RD, a menudo superando a expertos humanos en consistencia y velocidad.
Por ejemplo, un estudio que utilizó combinaciones avanzadas de redes neuronales evaluó su rendimiento en la clasificación de etapas de RD a partir de imágenes retinianas. El modelo propuesto mostró un potencial significativo para mejorar las capacidades de diagnóstico en la detección de RD.
Los beneficios de la implementación de CNN en la detección de RD incluyen:
- Escalabilidad: El análisis automatizado puede manejar grandes volúmenes de imágenes, lo que permite programas de cribado a gran escala.
- Consistencia: Las CNN proporcionan evaluaciones uniformes, reduciendo la variabilidad asociada con el juicio humano.
- Accesibilidad: Desplegar herramientas basadas en CNN en entornos de atención primaria mejora el acceso a servicios de diagnóstico temprano, particularmente en áreas desatendidas.
A pesar de estas ventajas, persisten desafíos, incluyendo la necesidad de conjuntos de datos etiquetados extensos, mejorar la detección de características sutiles y abordar preocupaciones sobre la interpretabilidad del modelo. Los investigadores están explorando métodos para mejorar la augmentación de datos, visualización de características y desarrollar marcos de IA explicables para abordar estos problemas.
Ventajas y Desventajas de las Redes Neuronales Convolucionales
Las Redes Neuronales Convolucionales (CNN) son herramientas poderosas en el campo del aprendizaje automático, sobresaliendo en tareas de reconocimiento de imágenes y visión por computadora. Sin embargo, como cualquier tecnología, presentan tanto fortalezas como limitaciones. Comprender estos aspectos es crucial para determinar su idoneidad para aplicaciones específicas.
Ventajas
Resultados de Última Generación
Las CNN sobresalen en tareas de reconocimiento de imágenes, ofreciendo un rendimiento de última generación en dominios como la salud, la conducción autónoma y la seguridad.
Aprendizaje Automático de Características
Aprenden automáticamente características jerárquicas a partir de datos en bruto, eliminando la necesidad de extracción y ingeniería de características manual.
Eficiencia Computacional
Cuando se optimizan para GPUs, las CNN procesan grandes conjuntos de datos de manera eficiente, lo que las hace adecuadas para aplicaciones de alto rendimiento.
Robustez
Las CNN demuestran robustez frente al ruido y variaciones en los datos, asegurando un rendimiento confiable en diversos escenarios.
Desventajas
Altos Recursos Computacionales
Entrenar CNN en grandes conjuntos de datos requiere un poder computacional sustancial, a menudo necesitando hardware especializado como GPUs o TPUs.
Falta de Interpretabilidad
Las CNN operan como modelos de caja negra, lo que dificulta interpretar sus procesos de toma de decisiones.
Grandes Requisitos de Datos
El entrenamiento efectivo requiere grandes cantidades de datos etiquetados, lo que puede ser una limitación en dominios con conjuntos de datos pequeños.
Si bien las CNN ofrecen un rendimiento inigualable en diversas aplicaciones, sus demandas computacionales y de datos destacan la importancia de evaluar los compromisos al elegir modelos de aprendizaje automático. Al equilibrar estos factores, las CNN pueden aprovecharse eficazmente para resolver problemas complejos.